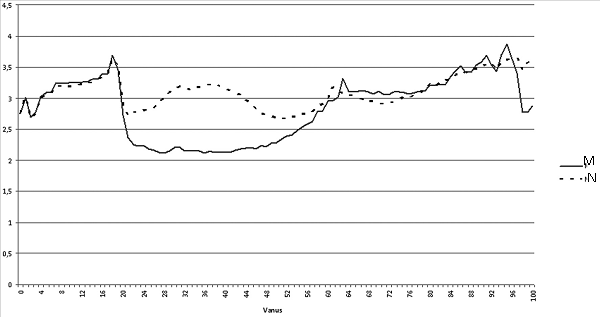

Jooned graafikul näitavad, mitmes riiklikus registris (eespool loetletud registrite hulgast) on keskmiselt esindatud erinevas vanuses mehed ja naised, kes elavad rahvastikuregistri andmetel Eestis. Allikas: Statistikaamet
Isikuankeetide identifitseerimine
Isikuankeetide (isikute) identifitseerimine kõlab kahtlaselt – kas see tõepoolest tähendab võimalust tutvuda isikustatud isikuandmetega? Nii see siiski ei ole. Kui kõik vastajad ja küsitlejad töötaksid ideaalselt hästi, siis poleks seda etappi üldse tarvis. Kahjuks aga laekus suur osa isikuankeetidest ilma isikukoodita – internetiloendusel hinnanguliselt kümnendik ja küsitlusel koguni üle kolmandiku. Pisut ootamatu oli see, et nimelt küsitlusel jättis suur hulk loendatavaid oma isikukoodi ütlemata. Oli isegi kuulda arvamusi, et loendatavad ei julgenud oma isikukoodi öelda, kartes, et keegi kasutab seda SMS-laenu võtmiseks!
Isikukoode on aga kindlasti tarvis kahel otstarbel. Esiteks seotakse isikukoodi abil loendusankeedi andmed andmetega, mida loendusel ei küsitud, vaid võeti mõnest registrist (nt õppimine). Teiseks on isikukoodid tarvilikud selleks, et andmestikust kõrvaldada duplikaatankeedid (kui ühe isiku kohta on laekunud mitu ankeeti).
Üks aegaviitvamaid tegevusi esmase andmekorrastuse protsessi ajal ongi isikukoodide lisamine ankeetidele. Nii suures osas, kui võimalik, toimub see automaatselt rahvastikuregistri abil, kusjuures aluseks on isiku nimi ja sünniaeg. Kui need andmed on õigesti märgitud, on ülesanne võrdlemisi lihtne: keskmiselt on iga päev sündinud ca 50 inimest ja nende hulgas sama ees- ja perekonnanimega inimesi juhtub võrdlemisi harva. Kui see juhtub, kasutatakse lisaks nt elukohta.
Asi läheb keeruliseks aga siis, kui lähteandmed pole õiged. Sünniaja puhul võib olla eksitus nii päevas kui ka aastas. Nimede puhul on eksimisvõimalusi palju. Kuulmise järgi üles kirjutades võivad segi minna Mati ja Matti, Avo ja Aavo, Kristiina ja Kristina, Anneli ja Annely, seda enam et ega iga kord loendajale vastav leibkonnaliigegi ei tarvitse isiku täpset nimekuju teada, kui igapäevakasutuses on hoopis hüüdnimi. Veelgi enam variante tuleb slaavi või mõne muu ladina tähestikust erinevas tähestikus originaalnime transkribeerimisel Eesti rahvastikuregistris esinevale nimekujule, mis on isikukoodi leidmiseks vajalik. Nii tekivadki identifitseerimisülesanded, mida programm automaatselt lahendada ei suuda ja kus appi peavad tulema operaatorid, kes näevad isiku mõningaid andmeid ankeedist ja samu andmeid rahvastikuregistrist, et neid kokku sobitada. Praeguseks on see töö enam-vähem lõpetatud, valdav enamik koodita ankeete on isikukoodid külge saanud ja andmebaasi kantud.
Siiski pole tarvis muretseda selle pärast, et identifitseerimise protsessis saavad operaatorid ankeete isikustatud kujul vaadata. Operaator näeb ankeedist ainult oma tööks hädavajalikku osa, hiljem aga analüüsitakse ankeete hoopiski ilma nimeta ja ka isikukoodid on teisendatud (krüptitud) nii, et neid konkreetse isikuga siduda pole võimalik.
Aadresside identifitseerimine
Olukord pole lihtsam ka aadressidega. Käesoleval ajal on Eestis olemas aadressi standardkuju, mis peaks võimaldama tuvastada kõiki eluruume. See kuju oli kasutusel ka loendusankeetides. Kuid oli võimalik standardkujust mööda minnes kasutada ka n-ö vabakäeliselt kirjutatud aadresse. Nii ongi standardse aadressi „Harjumaa, Tallinna linn, Kesklinna rajoon, Endla tänav, maja nr 15” kõrval ka aadress kujuga „Tallinn, Endla 15” ja veel mitmesuguseid muid aadressikujusid. Selleks et iga eluruum oleks andmestikus korrektselt esindatud ja nt nurgamajad ei esineks andmestikus kahe hoonena, on tarvis ka aadressiandmed korrastada. Taas on oluline osa sellest tööst tehtav programmiliselt, kuid keerukamad probleemid tuleb lahendada operaatoritel. Aadresside osas on käesoleva loenduse puhul tööd ja probleeme rohkem kui varasematel loendustel, sest iseloendamisel kirjutasid inimesed oma aadressi üles ise. Ülesande muudab keerukamaks (aga tulemuse loodetavasti märksa täpsemaks) ka elukohtade märkimine kaardil, mis sellisel kujul oli Eestis esmakordne ja iseloendusena võrdlemisi uudne ka maailma mastaabis. Uudne oli ka see, et inimene võis märkida enesele kaks elukohta – peamise ja teisese. Seegi suurendab tööd aadresside täpsustamisel.
Kodeerimine
Kolmas töö, mida operaatorid viimase kuu jooksul on teinud, on kodeerimine. Lihtsustatult tähendab see tekstiliste ankeedivastuste asendamist numbrite, nn koodidega. See puudutab eeskätt ameteid ja tegevusvaldkondi, samuti osaliselt murrakuid, uskusid jm. Rahvusvaheliselt on välja töötatud klassifikaatorid niihästi ametite kui ka tegevusvaldkondade jaoks, kusjuures need klassifikaatorid, mis sisaldavad tuhandeid detailselt kirjeldatud alajaotusi, on universaalsed kogu maailma jaoks, haarates nii kartulite kui ka banaanide kasvatajaid, kooli- ja lasteaiaõpetajaid, kirikuõpetajaid ja vangivalvureid, ministreid ja kojamehi.
Need klassifikaatorid on aja jooksul märgatavalt muutunud vastavalt sellele, kuidas uusi ameteid ja tegevusvaldkondi on juurde tekkinud. On ka ameteid, mida tänapäeval enam ei tunta või mis on uue vormi saanud – näiteks voorimees, mis esimese rahvaloenduse ajal oli levinud amet Tallinna eesti soost meeste seas. Kõigi loenduste puhul on elukutsete ja ametite tüüpliigendus olemas olnud ja ametite/elukutsete sorteerimine sobivatesse klassidesse on toimunud alati. Üks huvitavamaid järeldusi, mida varasemate rahvaloenduste andmete põhjal on võimalik teha, ongi eri ametite sagedus ühiskonnas ja selle muutumine. Esimeste Eestis toimunud rahvaloenduste ajal olid n-ö valgekraelised ametid valdavalt sakslaste kanda, militaarseid täitsid venelased ja eestlaste osaks oli lisaks põllutööle ka töö vabrikutes, aga ka teenijaks olemine. Viie esimese rahvaloenduse ajal oli eestlaste põhiliseks tegevusvaldkonnaks põllumajandus.
Duplikaatide töötlus
Järgmine samm, mis loendusandmetega tehakse, on duplikaatide töötlus. Üks osa isikuid on loendatud korduvalt – näiteks on tema ankeedi täitnud abikaasa, laps ja lõpuks ka ta ise. Ise mitu korda ankeeti täita polnud võimalik, kuid pereliikmeid, kes teiste ankeete täitsid, võis olla mitu. Nii tekkisid duplikaatankeedid, mille hulgast tuleb välja valida kõige õigem, nn originaal ja ülejäänud arvestusest välja jätta. Kuigi minu hea kolleeg arvutiteaduse instituudist arvas, et isikukoodide olemasolul on unikaalsete ankeetide hulga määramine ühe hiirekliki ülesanne, siis tegelikus elus on asi siiski pisut teisiti.
Käesoleval loendusel koguti isikuandmeid mitmesuguste ankeetide ja dokumentide abil. Lisaks püsielaniku ankeetidele (püsielanikud moodustavadki Eesti rahvaarvu) olid kasutusel veel ajutiste elanike ankeedid (neid täitsid niihästi isikud, kelle püsielukoht on Eestis kui ka need, kelle püsielukoht on välismaal), Eestist lahkunute ankeedid, mida täitsid lähisugulased. Mõnest asutusest (nt sügava puudega isikute haigla või hooldekodu) laekusid loendamisele kuuluvate isikute nimekirjad. Olemas on ka niisuguste isikute isikukoodide loetelu, kes püüdsid end välismaal loendada, kuid kelle loendamine peatati, sest nad märkisid oma püsielukoha riigiks välismaa. Iga sellise isikutekategooria kohta on selge, kas ta loetakse Eesti püsielanike hulka või mitte. Nii ei ole Eesti püsielanikud need, kes on siit (omaste kinnitusel) lahkunud, samuti välismaal püsivalt elavad isikud (hoolimata sellest, et nad ennast soovisid loendada) ja ka need isikud, kes elavad Eestis ajutiselt (3–12 kuud), kuid kelle püsielukoht on välismaal.
Asja teeb aga kee
rukaks see, et mitmekümne tuhande isiku puhul on olemas vasturääkivaid duplikaatankeete. Näiteks – inimene on ennast püüdnud loendada välismaal, protsess on katkestatud ja selle järel on ta tulnud Eestisse ja siin täitnud omakäeliselt püsielaniku ankeedi. Üsna tüüpiline on ka olukord, et isiku kohta on näiteks ema täitnud püsielaniku ankeedi, õde või vend aga kinnitab, et ta on välismaale lahkunud. Kõigi nende olukordade puhuks on tarvis välja töötada vettpidavad otsustuseeskirjad, mis on kooskõlas rahvusvaheliste reeglite ja loenduste hea tavaga ja mis võimaldavad otsustada, kas isik on Eesti püsielanik või mitte.
Kõige olulisem ja kõige vanem neist tavadest on loendusandmete usaldamine. Loendusandmeid üldjuhul ei võrrelda teiste allikate (nt registrite) andmetega ja teisi andmeallikaid kasutatakse loendusandmete täiendamiseks üksnes sel juhul, kui loendusandmetes on mingi näitaja puudu või selgelt vastuoluline (nn jäme viga).
Loendusele eelnevas teavitustöös selgitati põhjalikult, millal on inimene Eesti püsielanik ja millal välismaalane, vastav selgitus oli ka ankeetidel kirjas, samuti teavitati põhjalikult loendajaid. Selle tõttu ei kontrollita seda, kas isik, kes on enese alaliseks elukohaks märkinud Eesti (või kelle on Eesti elanikuks märkinud tema leibkonnaliikmed), tõepoolest Eestis elab. Mittekontrollimise põhjuseks on ka see, et loendamisele kuuluvad rahvusvaheliste reeglite kohaselt ka illegaalselt riigis viibivad isikud, keda ükski register ei kajasta. Küll aga tuleb analüüsida olukordi, kus loendusel laekunud info on vastuoluline.
Kui duplikaate on täitnud eri isikud, siis loetakse primaarseks (originaaliks) see ankeet, mille on täitnud isik ise või alla 15aastase lapse vanem. Kui aga originaalis osa andmeid puudub, siis täiendatakse seda duplikaatide põhjal, loomulikult kontrollides lisatavate andmete kooskõla originaali andmetega. Pärast originaalide väljavalimist ja ülearuste duplikaatide kõrvaldamist on võimalik öelda loendatud isikute ja loenduse käigus selgunud lahkunute arv. Mõlema arvu puhul tuleb aga arvesse võtta, et tegemist on loendusel laekunud infoga, mis paratamatult ei ole absoluutselt kõikne ja täpne.
Loendusandmete üle- ja alakaetus
Varasematel loendustel ongi loendatud isikute arvu käsitletud rahvaarvuna. Tegelikult see päris õige ei ole. Alati on juhtunud seda, et osa inimesi on jäänud mingil põhjusel loendamata, selle tagajärjel on loendustulemus tegelikust rahvaarvust väiksem. Niisugust olukorda nimetatakse alakaetuseks ja alakaetuse määraks on loendamata jäänud inimeste arvu suhe rahvaarvusse (tavaliselt protsentides). Loendamisel saab tekkida teinegi viga – loendatakse liiga palju inimesi. Siis on tegemist ülekaetusega. Ülekaetuse määraks on liigselt loendatud inimeste arvu suhe rahvaarvusse. Ülekaetuse põhjuseks võib olla näiteks ajutiste elanike loendamine püsielanikena, kuid kõige sagedamini isikute korduv loendamine. Ajalooliselt on rahvas suhteliselt vähe liikunud, mistõttu alakaetus ning ülekaetus on olnud võrdlemisi väikesed ning enam-vähem tasakaalus. Pealegi polnud täpsemat tegeliku rahvaarvu hinnangut kusagilt võtta ja selletõttu on rahvaloenduse tulemuse kasutamine rahvaarvuna olnud õigustatud. Seda tehakse praegugi väga paljudes maades.
Tänapäeval on arenenud maades rahvaloenduste korraldus, aga ka kvaliteedinõuded muutunud. Ülekaetust õnnestub isikukoode arvestades peaaegu täielikult vältida, alakaetus on aga kogu maailmas väga tõsine probleem. Inimesed on liikuvad, neil on mitu elu- ja töökohta ja loendajatel on raske neid kätte saada. Lisaks sellele varjab mingi hulk inimesi kiivalt oma isikuandmeid, lugedes nende avaldamist privaatsuse riiveks. On ka mitmesuguseid muid põhjusi, miks mingi osa inimesi jääb loendamata. Siit tulenebki tõdemus: loendatud isikute arv ei ole tänapäeval täpselt sama, mis tegelik rahvaarv ja peamiseks loenduse probleemiks on alakaetus.
Eesti REL2011 alakaetus
Ka Eestis on loendusjärgselt tulnud teateid loendamata jäänud inimestest. Toon siin kaks tüüpilist näidet, mis on meediaski kajastust leidnud.
„Mind rahvaloendaja ei soovinud loendada, ütles, et minu korteris on juba kõik loendatud … Minu korterisse on sisse kirjutatud minu tütar, kes elab mujal, sest ma soovin, et tema päriks minu korteri. Tütar loendas ennast internetis …”. Siin on tegemist tüüpolukorraga, mida ka loenduse korraldajad ette nägid, kuid mille vastu on peaaegu võimatu rohtu leida. Kui inimesed internetis loendasid end valel aadressil, kõige sagedamini sellel aadressil, kuhu nad on ametlikult registreeritud, ja märkisid, et selles eluruumis on kõik isikud ja kõik leibkonnad loendatud, siis loendajad seda eluruumi ei külastanud ja selles tegelikult elavad inimesed, kes polnud end internetis loendanud, jäidki loendamata. Toodud näite puhul on segaduses süüdlane mehe tütar, kes täitis ankeedi isa eluruumi kohta ega märkinud, et selles korteris elab ka tema isa.
Teine näide puudutab Tartu Supilinna. Küsitletud meesterahvas kõneles poe juures reporterile: „Mina ei ole loendajat näinud. Ta on küll minu maja juures käinud, aga ma elan teisel korrusel ja mul on uksed lukus. Postkasti oli ka sedeli jätnud, aga ma leidsin selle alles hiljem.”
Kummagi näite puhul pole alust süüdistada loenduse korraldust ega ka loendajate tegevusetust, pigem on tegemist loendatavate ettearvamatu käitumisega.
Paratamatult on Eestis arvestatav hulk ka selliseid inimesi, kes postkasti ei vaata, ust peavad lukus, telefoni ei kasuta ja kes selle tõttu on loendamata jäänud, kuigi nad on Eesti riigi püsielanikud. Nende „püüdmiseks” pakuti loendusmeeskonna poolt veel mitut võimalust – loendaja kojukutsumine telefoni teel, enesest märku andmine veebilehel –, aga ega ka see sõnum kõigini jõudnud.
Seda arvestades võib oletada, et loendusandmed on 1–2% võrra alakaetud, st et nii palju inimesi on loendamata jäänud. Rahvusvahelises võrdluses pole see tulemus iseenesest halb, kuid kindlasti ei rahulda see teadmine kõiki neid, kes soovivad teada saada täpset Eesti rahvaarvu ja seda mitte ainult ühe numbrina, vaid soo-vanuse-rahvuse jaotusena koos täpse geograafilise paiknemisega.
Eestist lahkunud isikute loenduspõhised andmed
Täiendavat teavet tegeliku rahvaarvu kohta annab loenduse käigus kogutud teave Eestist lahkunud inimeste kohta. Kahjuks ei ole see teave päris täielik, sest kui mõni leibkond on täies koosseisus lahkunud, siis ei tarvitse ükski inimene nende kohta ka lahkunu ankeeti täita. Seega võib arvata, et loenduse käigus kogunenud lahkunute andmestik on veelgi enam alakaetud, võrreldes loendatud Eesti elanike andmestikuga.
Mida tuleb teha selleks, et saada teada Eesti tegelikku elanike arvu?
Järgmine tööetapp, mis RELi meeskonnal ees seisab, ongi tegeliku Eesti elanike arvu hindamine. Selleks rakendatakse Eestis olemasolevaid registreid, kusjuures andmete sidumiseks kasutatakse krüptitud koode, mis isikute tuvastamist ei võimalda.
Kuigi Eesti registrid on valdavalt loodud ja käivitatud viimase kümmekonna aasta jooksul, mistõttu need on võrdlemisi noored ja nende kvaliteet polnud kindlasti piisav selleks, et 2011. aasta loendus teha täies ulatuses registrite põhjal, sisaldavad need siiski üsna palju teavet, mida on võimalik kasutada Eesti rahvastiku arvukuse hindamiseks.
Rahvastikuregister. Üks kõige vanemaid ja korrektsemaid registreid Eestis on rahvastikuregister, mis põhimõtteliselt peaks kajastama kõiki Eesti elanikke koos nende põhiandmetega, mille hulgas kõige olulisemad on isikukood ja elukoht. Kahjuks nimelt elukoha andmed ongi rahvastikuregistri kõige nõrgem koht. Kuna Eestis elukoha registreerimine ei olnud aastate jooksul kohustuslik ja praegugi on kohustuslik üksnes formaalselt (seda üldiselt ei kontrollita), samal ajal kui on rida ajendeid elukoha ekslikuks registreerimisek
s (omavalitsuste soodustused, koolide jm eelistused), siis ei vasta rahvastikuregistri elukoht inimese tegelikule elukohale umbkaudu viiendikul juhtudest. Kahjuks on nende juhtude hulgas ka sellised, kus inimene on Eestist lahkunud, kuid jäänud registris Eesti elanikuks. See pole etteheide registrile, vaid pigem seadusandlusele ja see kajastab Eesti võrdlemisi nõrka registrikultuuri ja lojaalsust, mis jääb oluliselt maha meile eeskujuks olevatest Põhjamaadest.
Võrreldes (krüptitud koodide alusel) rahvastikuregistri andmetel loendusmomendil Eestis elanud isikute loetelu loendatud isikute loeteluga on võimalik leida loendamata jäänud isikud. Õnneks ei ole niisuguste isikute arv kuigi suur, piirdudes mõne protsendiga loendatud isikute arvust. Nende puhul on kaks võimalust: nad kas elavad Eestis ja jäid loendamata või nad on Eestist lahkunud ilma oma lahkumist registreerimata. Iga sellesse loetelusse kuuluva isiku kohta tuleb langetada otsus kumba kategooriasse ta kuulub: kas ta on Eesti püsielanik või on Eestist lahkunud.
Nende isikute kohta, keda loendusel ei loendatud ei püsielanikuks ega ka lahkunuks, tuleb leida täiendava info allikad. Selleks saab kasutada kõiki Eestis toimivaid registreid. Nende seas on olulisemad ravikindlustuse andmekogu, mis sisaldab üle 90% Eesti inimestest, maksukohustuslaste register, mis katab olulise osa tööealisest elanikkonnast, Eesti Hariduse Infosüsteem (EHIS), mis sisaldab peaaegu kõigi õppijate andmed, olles seega väga hea allikas kooliealiste isikute tuvastamiseks. Üsna palju täiendavat infot on võimalik saada veel riiklikust pensionikindlustuse registrist (sisaldab nii pensione kui ka peretoetusi), sotsiaalteenuste ja -toetuste andmeregistrist (STAR), samuti ka liiklusregistrist, mis sisaldab niihästi sõidukijuhtide kui ka -omanike andmeid.
Vaadates kõigis nimetatud registrites 2011. aastal aktiivselt mingeid toiminguid teinud isikuid, selgub, et keskmiselt on iga Eesti elanik aasta jooksul fikseeritud (lisaks rahvastikuregistrile) veel kolmes registris. Kuid on ka selliseid isikuid, kes on küll rahvastikuregistri andmetel märgitud Eesti elanikuks, kuid kelle kohta aasta jooksul üheski muus registris ühtegi märget ei ole tehtud. Loogiline on arvata, et niisugune inimene on Eestimaa tolmu jalgadelt pühkinud. Nende kohta tulebki langetada otsus, et nad ei kuulu Eesti püsielanike hulka.
Seevastu inimesed, kes on lisaks rahvastikuregistrile veel mitmes registris aktiivsete tegutsejatena kirjas, elavad suure tõenäosusega Eestis ja on loendamata jäänud kas sellepärast, et nende aadressil loendati kedagi teist või sellepärast, et nad loenduse ajal olid ajutiselt välismaal. Niisugust otsust ei saa siiski langetada ainult ühe registri põhjal, sest küllap on ka selliseid inimesi, kes kasutavad mõningaid Eesti sotsiaalteenuseid, olles ise välismaale elama asunud. Õnneks on aga Eestis registreid palju ja nende info kokkupanemine ja selle detailne analüüsimine annab üsna usaldusväärse tulemuse.
Eesti rahvaarvu määrataksegi, lisades loendatud inimeste arvule juurde need isikud, kes jäid loendamata, kuid arvestades muud infot (kõiki toimivaid registreid) väga suure tõenäosusega elavad püsivalt Eestis. Kõik see võtab aga aega, sellepärast ei ole esimene loendatute arvu hinnang kindlasti päris täpne ja seda tuleb pärast täpsustada, samuti tuleb samm-sammult täiustada mitteloendatud Eesti elanike arvukuse hinnangut ja ka loendustevahelisel perioodil registreerimata emigreerunute arvu hinnangut.
Paratamatult jääb ikkagi alles teatav eksimise võimalus. Võib-olla jääb kõigest hoolimata Eesti püsielanike loetelust välja meesterahvas Supilinnast, kes elatub pudelite korjamisest ja sotsiaalabi ei vaja, pensioniikka ei ole veel jõudnud ning ei ole olnud juhust ka arsti juurde sattuda ning selle tõttu pole tema tegevusest viimase aasta jooksul üheski registris ühtegi jälge.
Loendusmeeskond püüab teha parima, et saada kogu olemasolevat infot kasutades võimalikult täpne elanike arvu hinnang. Statistikute jaoks ei ole parim mitte „võimalikult suur”, vaid „võimalikult täpne”. Igal juhul on aga juba praegu, mil andmete esmane töötlus ei ole veel lõpetatud, selge, et mingeid kapitaalseid üllatusi Eesti rahvaarvu suuruses – ei pluss- ega ka miinuspoolele – karta ega oodata ei ole alust.